Atelier Topic Modeling
Découvrir Bertopic et le pouvoir des encodeurs
2026-07-05
Au coeur : la représentation des textes — depuis 2017
- Approches par les plongements sémantiques grâce à des modèles pré-entraînés (souvent BERT):
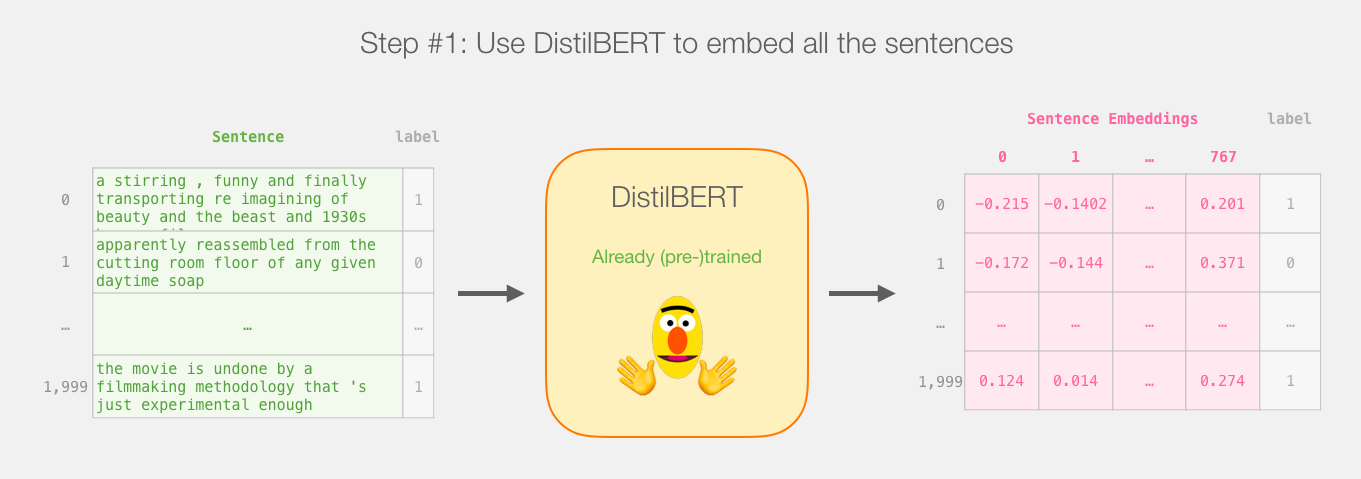
A Visual Guide to Using BERT for the First Time - Jay Alammar, source
Différence majeures:
- Pré-traitement moins central
- Prise en compte du contexte dans la représentation
- Représentation dense
- Matériel computationnel plus lourd
Un mot sur les plongements sémantiques1
On ne se contente plus d’observer la présence de mots, on cherche à identifier leur sens dans leur contexte.
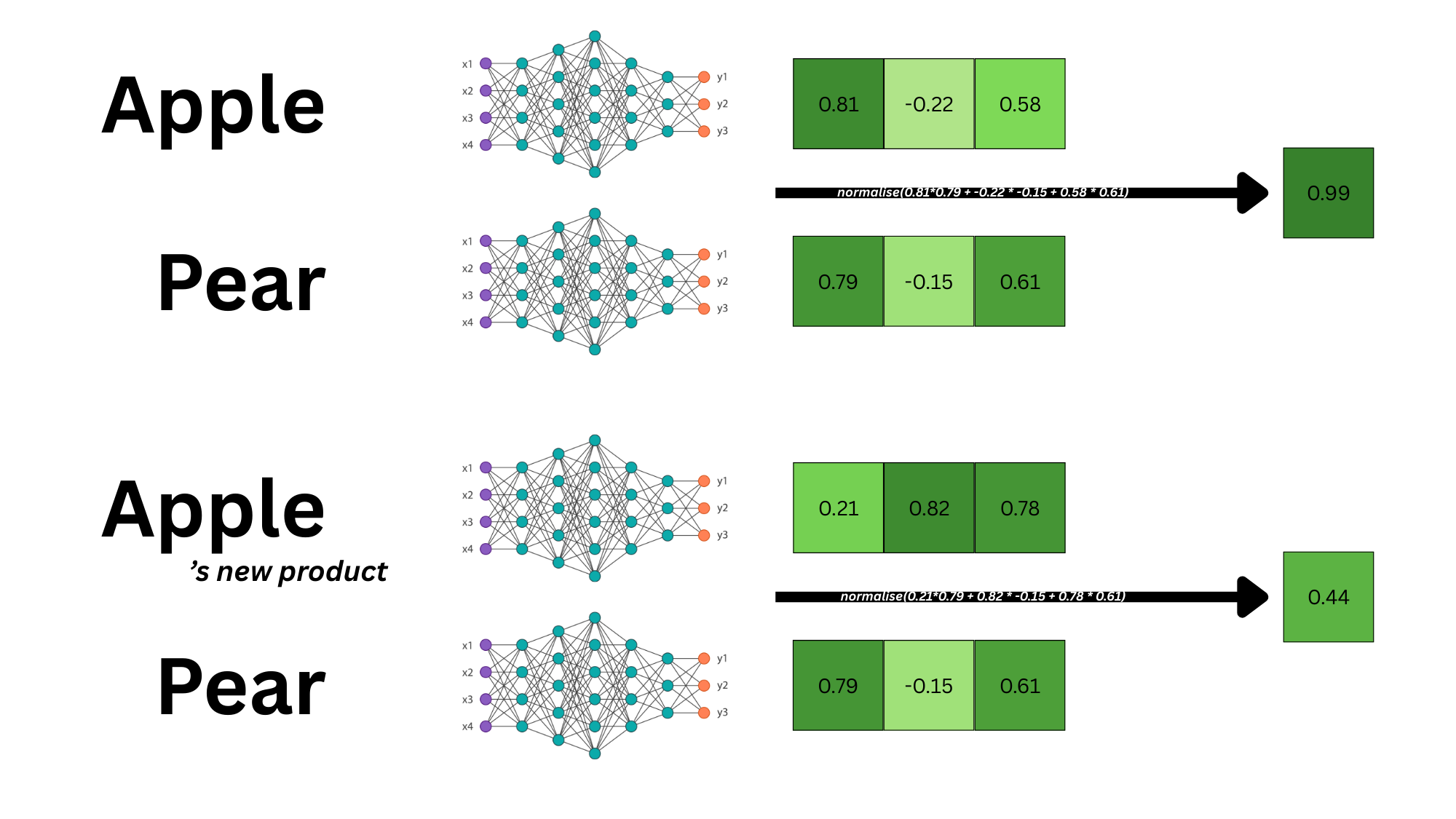
Bertopic dans tout ça ?
Un projet qui facilite la manipulation de ces distances sémantiques pour extraire des thèmes (et faire plein d’autres choses : visualiser, etc.). Ce projet rassemble :
Ce qu’il fait
Un pipeline de méthodes de machine learning

Qui permettent la modularité
Et donc de s’adapter aux enjeux spécifiques du traitement

Une adoption en croissance
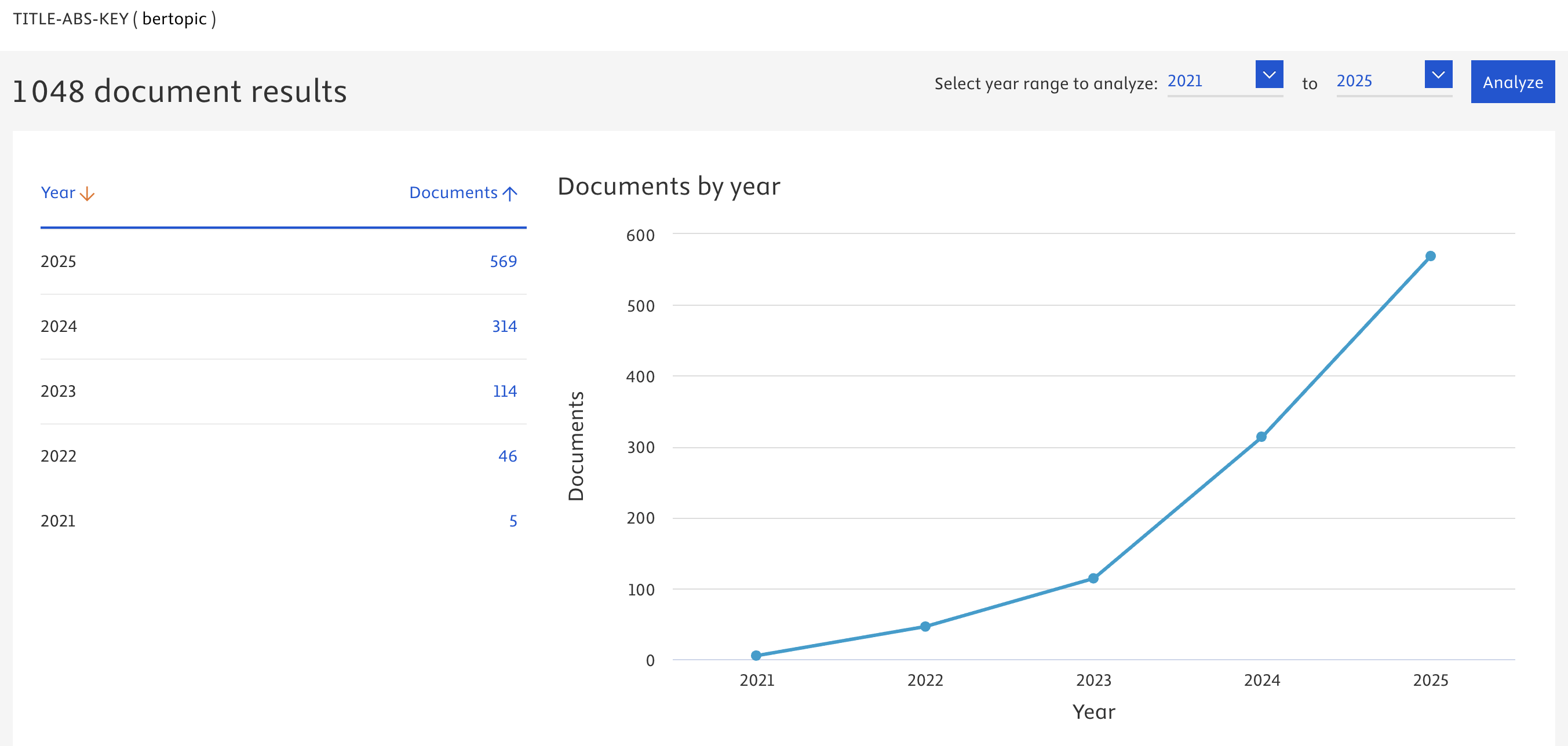
« they valued BERTopic’s ability to uncover hidden connections, emphasizing the need for meaningful, comprehensive analysis tools that support their research objectives and enhance data interpretation » (Kaur et Wallace, 2024, p. 2) (pdf)
Quelques débats … pas toujours très justes
De bonnes raisons de tester Bertopic (au moins)
- Package bien pensé et facile d’usage
- Mobilise la puissance des modèles pré-entrainés
- Hautement configurable pour les cas particulier
- Tire parti des modèles BERT récents
- Propose une documentation et des formations de qualité, en plus d’une communauté active !
Lancer son premier topic model avec BERTopic
import pandas as pd
from bertopic import BERTopic
df = pd.read_csv("./theses-soutenues-curated-stratified.csv")
docs = df["resumes.fr"].sample(1000).to_list()
topic_model = BERTopic(language="french")
topic_model.fit(documents=docs)
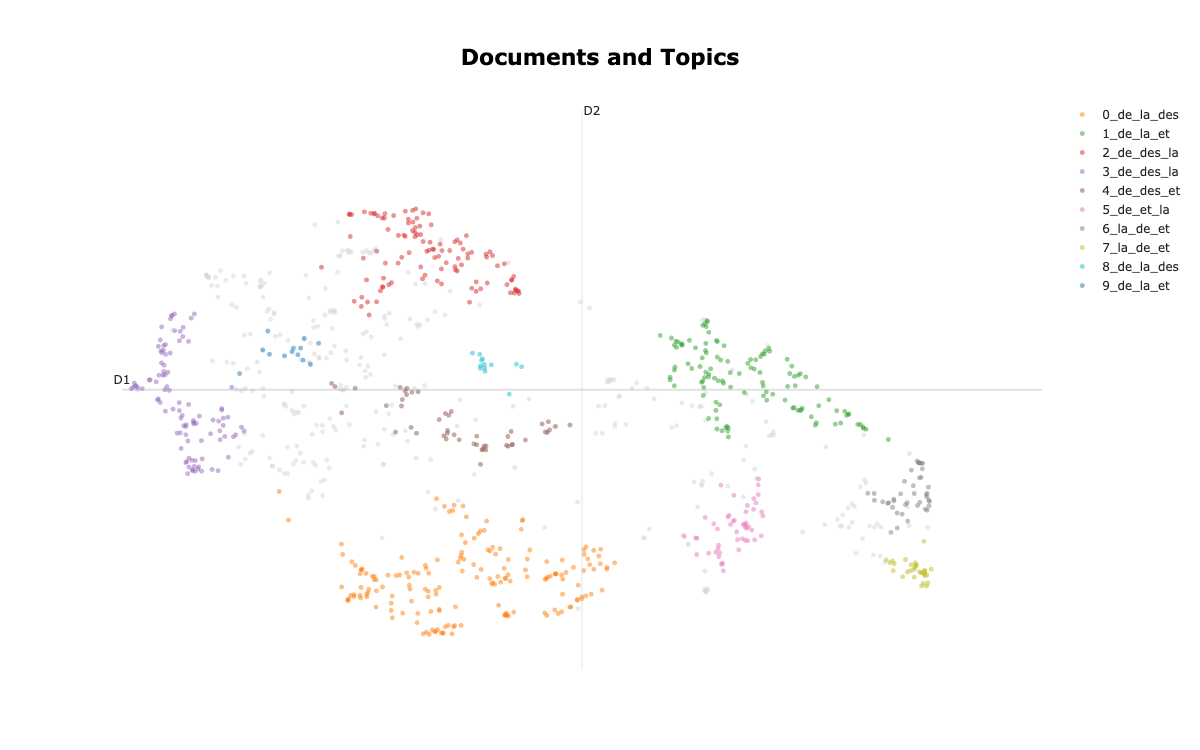
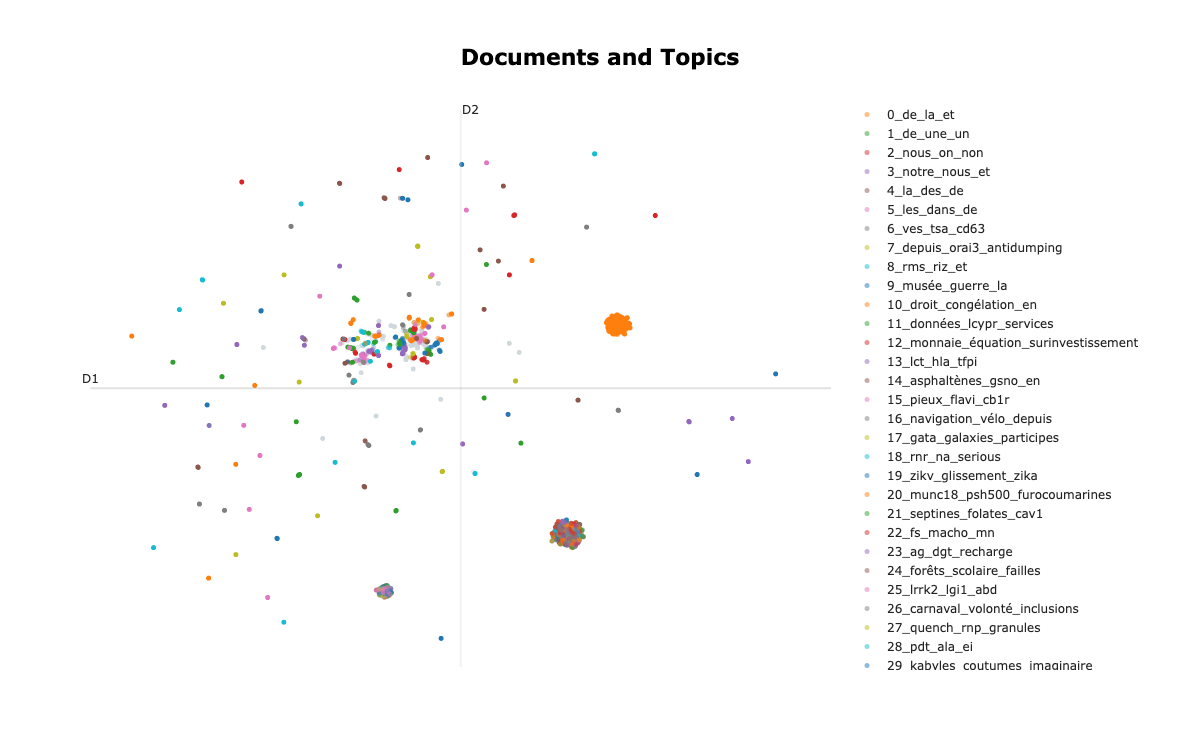
Voyons ce que ça donne - Afficher les documents dans un espace 2D
On cherche à afficher les documents dans un espace 2D pour identifier la taille des clusters et leurs position relative.
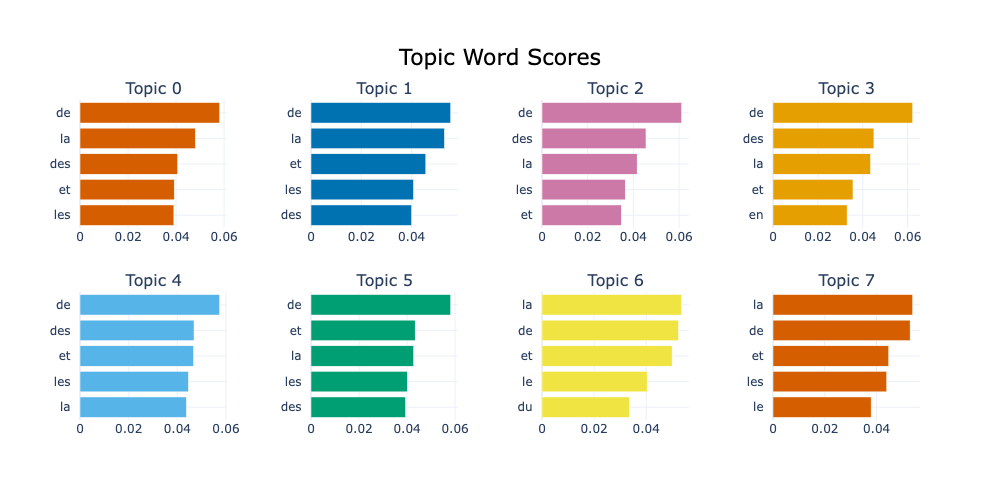
Voyons ce que ça donne - Afficher les mots clefs
On cherche à afficher les mots clefs de chaque thème pour facilement les comparer
Voyons ce que ça donne - Explorer les interactions entre les thèmes
On cherche à identifier la structure interne au modèle et les proximités entre les thèmes et comment ils s’emboitent.
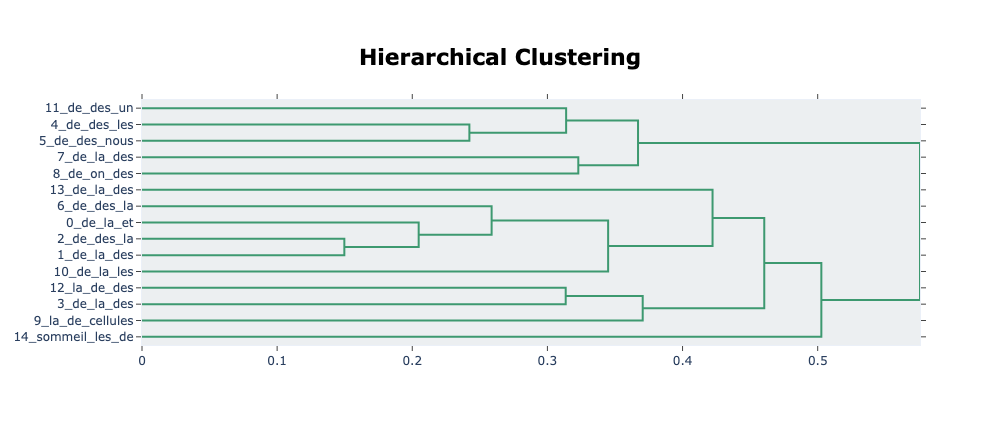
Cette visualisation ouvre la question de la fusion de thèmes qui est rendu possible par BERTopic.
On en parle au cas pas cas.
Voyons ce que ça donne - Tentons d’évaluer le modèle
# code_oai = "ddc:300" # "Sciences sociales, sociologie, anthropologie",
# code_oai = "ddc:340" # "Droit",
# code_oai = "ddc:004" # "Informatique",
# code_oai = "ddc:570" # "Sciences de la vie, biologie, biochimie",
# code_oai = "ddc:540" # "Chimie, minéralogie, cristallographie",
# code_oai = "ddc:620" # "Sciences de l'ingénieur",
# code_oai = "ddc:550" # "Sciences de la terre",
code_oai = "ddc:530" # "Physique",
# code_oai = "ddc:510" # "Mathématiques",
# code_oai = "ddc:610" # "Médecine et santé"
doc_contains_code_oai = df_sample["oai_set_specs"].apply(lambda s: code_oai in s.split("||"))
topics_per_class = topic_model.topics_per_class(docs, classes=doc_contains_code_oai)
topic_model.visualize_topics_per_class(topics_per_class)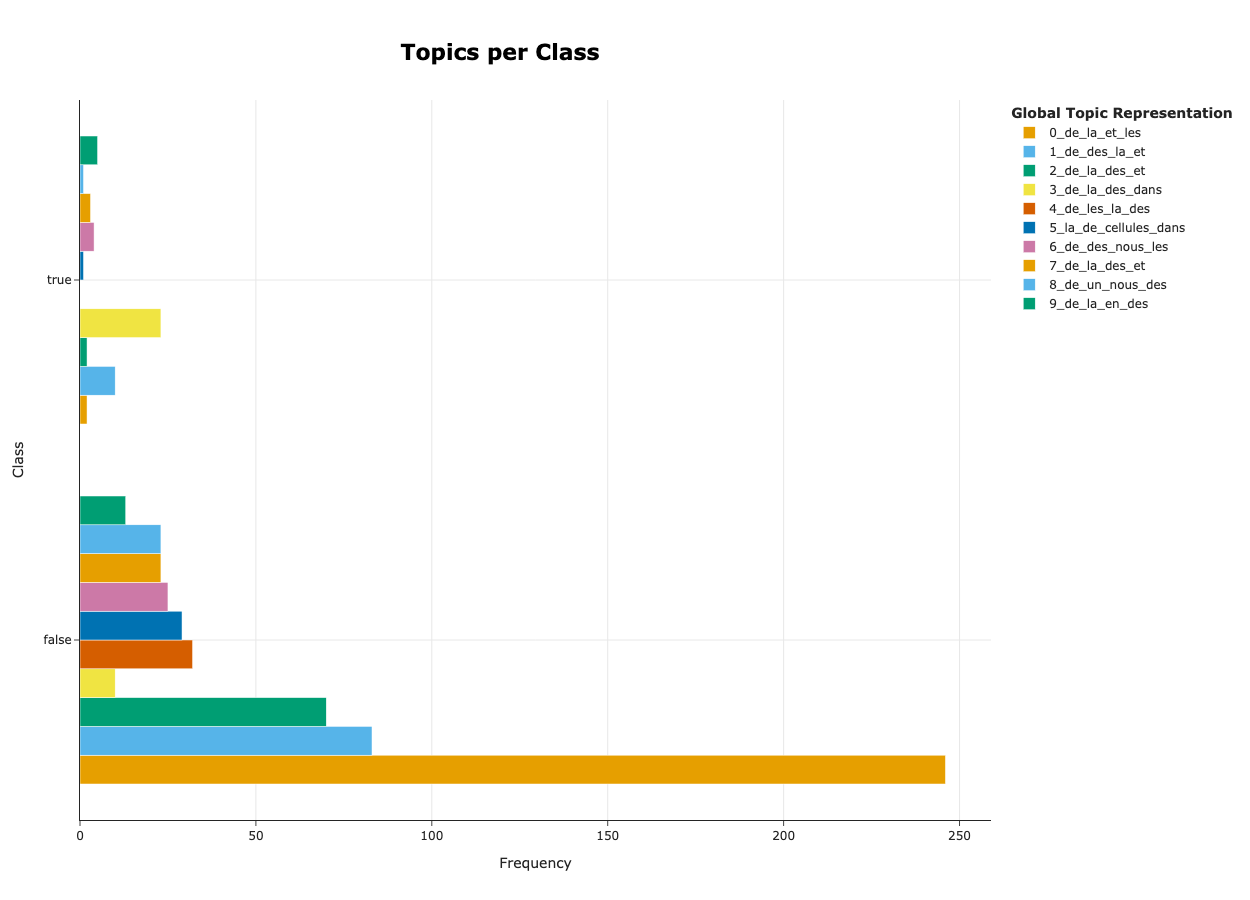
Après affinage, on peut obtenir des résultats très satisfaisant !
Après affinage et vérification, on obtient les résultats suivants :

Rappel de la pipeline

Impact du changement de modèle




Pour la suite on va utiliser gte-multilingual-base-fr-SBERT.
Réduction de dimensionalité avec UMAP
- Hyperparamètres impliqués:
n_neighorsetn_components(conservermin_dist=0.). - Objectif: Réduire le nombre de dimension (i.e. la taille des vecteurs) pour passer de plusieurs centaines à 2-10.
- Technique employée: UMAP (Uniform Manifold Approximation and Projection), une technique qui cherche à reconstruire un réseau de distances relatives en plus basse dimension de manière itérative. D’autres techniques sont possibles: PCA ou t-SNE.
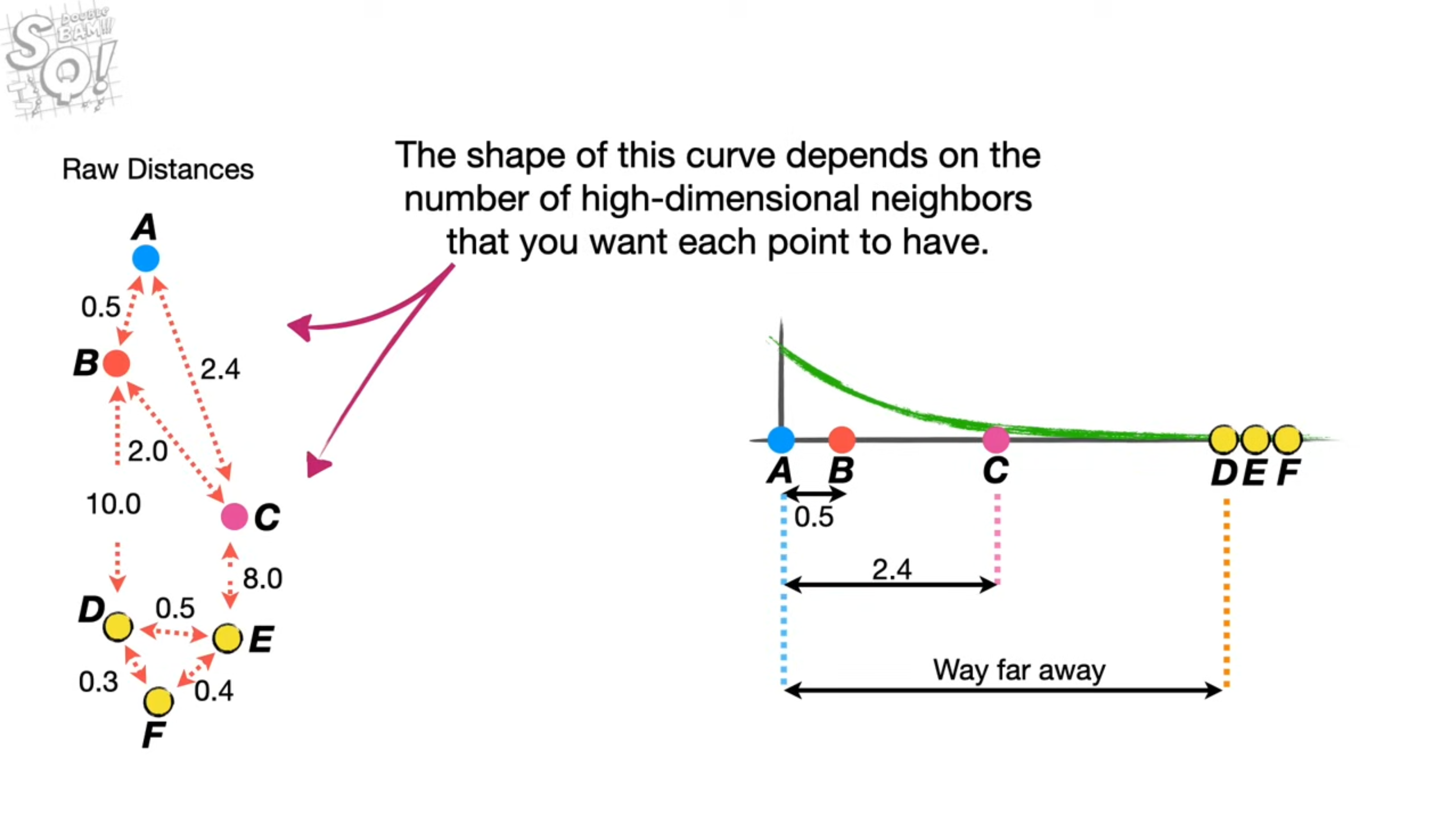
UMAP Dimension Reduction, Main Ideas!!! - StatQuest with Josh Starmer source
Ressource pour jouer avec les paramètres: Understanding UMAP
Impact du changement de n_neighbors

n_neighbors = 5
n_neighbors = 15 (default)
n_neighbors = 300Warning
Attention, en fonction de la taille du corpus, une valeur “raisonnable” de n_neighbors va changer !
🚨Attention🚨 ici la représentation visuelle ne change pas, malgré qu’on ai changé n_neighbors. C’est normal, en réalité il y a 2 UMAP:
- premier UMAP: celui appliqué sur les embeddings, qui réduit à 5 dimensions, avec la valeur de
n_neighborschoisie, et dont les vecteurs résultants (en 5D), et sur lequel on applique l’algorithme de clustering. - deuxième UMAP: celui appliqué lorsqu’on utilise la fonction
topic_model.visualize_documents, qui réduit les embeddings à 2 dimensions, et utilisen_neighbors=10. D’où le fait que la visualisation ne bouge pas.
Impact du changement de n_components

Clustering avec HDBSCAN
- Hyperparamètres impliqués :
min_cluster_size. - Objectif : Créer des groupes à partir de patterns de proximité.
- Technique employée : HDBSCAN une technique de clustering qui cherche des clusters denses sans présupposer de leur forme et en acceptant que certains points soient considérés comme “bruit”. D’autres techniques sont possibles: DBSCAN, K-means.

HDBSCAN, Fast Density Based Clustering, the How and the Why - John Healy source
Ressource pour comprendre HDBSCAN: Documentation HDBSCAN - How HDBSCAN Works
Impact de min_cluster_size

min_cluster_size = 5
min_cluster_size = 10 (default)
min_cluster_size = 50Warning
Attention, en fonction de la taille du corpus, une valeur “raisonnable” de min_cluster_size va changer !
Impact du fait de retirer les stopwords



Annexe : Evaluer les topic models
Une histoire compliquée « standard metrics may not reliably reflect human perception of coherence in specialized fields » (Prouteau et al., 2026, p. 8) (pdf)

Annexe : Utiliser ActiveTigger
Comment découper son corpus ?