La reproductibilité des notebooks computationnels
Meetup INSEE Science Ouverte 2026
2026-05-21
Le périmètre (large) des notebooks computationnels
De quoi parle-t-on ? Un format qui lie code et contenu inspiré de la programmation lettrée (literate programming) reposant sur un environnement d’exécution
- Des notebooks interactifs avec kernel : Mathematica, Jupyter, Marimo…
- Des notebooks statiques à compiler : Quarto, RMarkdown
- Des solutions intermédiaires : le cas de Rmarkdown notebooks in RStudio
- Des intégrations dans des plateformes data : Databricks, Deepnote, Kaggle…
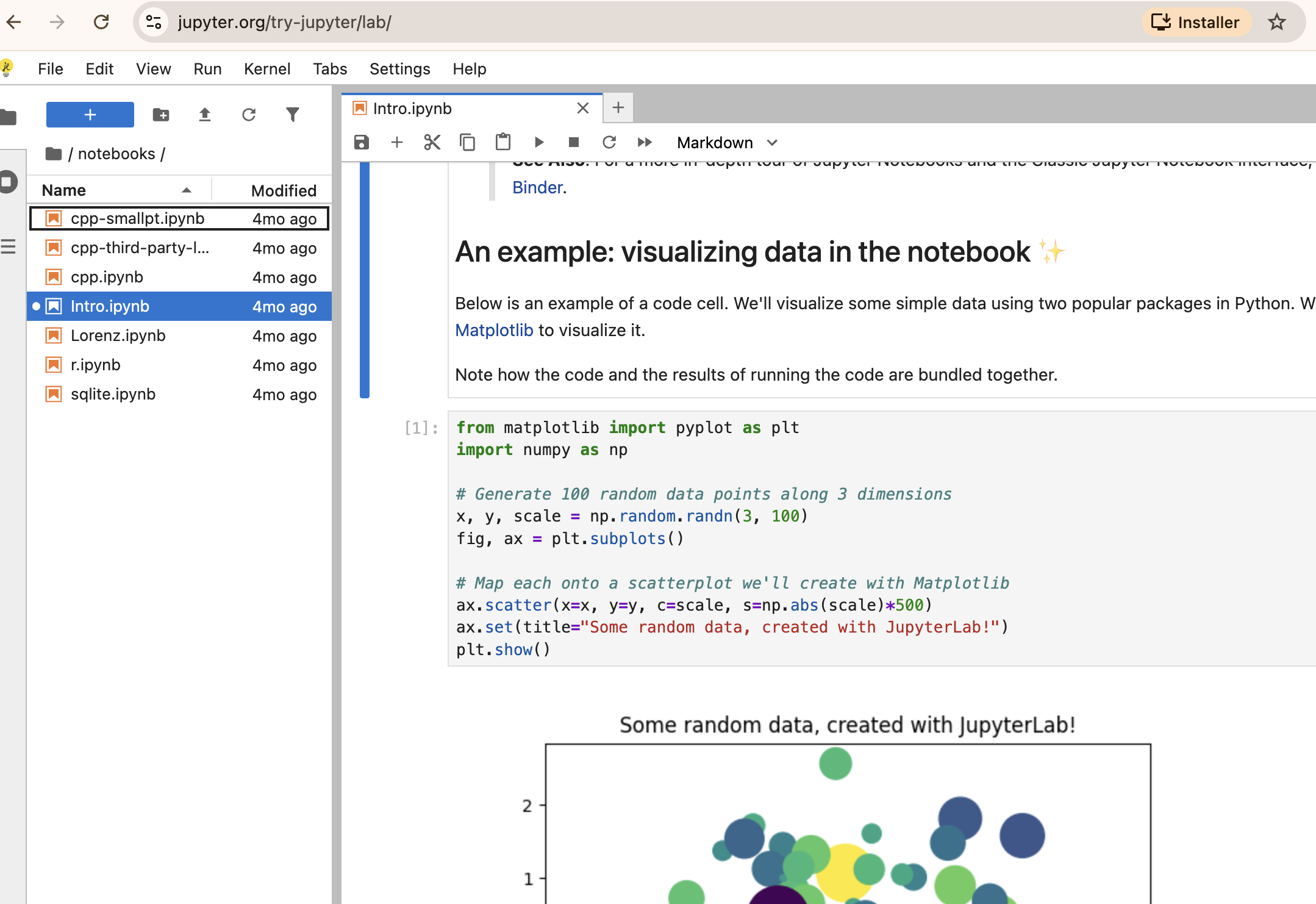
Les notebooks computationnels dans ma vie
Pas un usage unique mais un spectre de pratiques (en Python uniquement)
- Test de package/API
- appel ollama, en local
- Doc de travail collaboratif
- analyse des missions du laboratoire, sur Onyxia
- Support finalisé de formation
- tutorial BERTOPIC sur un dépôt public

Et en parallèle : des scripts, des fichiers markdown, etc.
La centralité du projet Jupyter
Un format ancré dans la programmation scientifique venu de la recherche (Schultz 2023).

“If you typed Python in the command line, you got a, an interactive shell, it was a very, very primitive and it didn’t allow me to do the kinds of things that were very natural in interactive scientific workflows with tools like IDL or Mathematica that I used heavily or Matlab or Maple that other used which was simply to type a bit of code, see the results right there, open a plot, look at the files on, on the file system, et cetera.” Fernando Pérez, 2012
Une promesse “native” de reproductibilité

Avoir le code et les résultats rapprochent de la reproductibilité
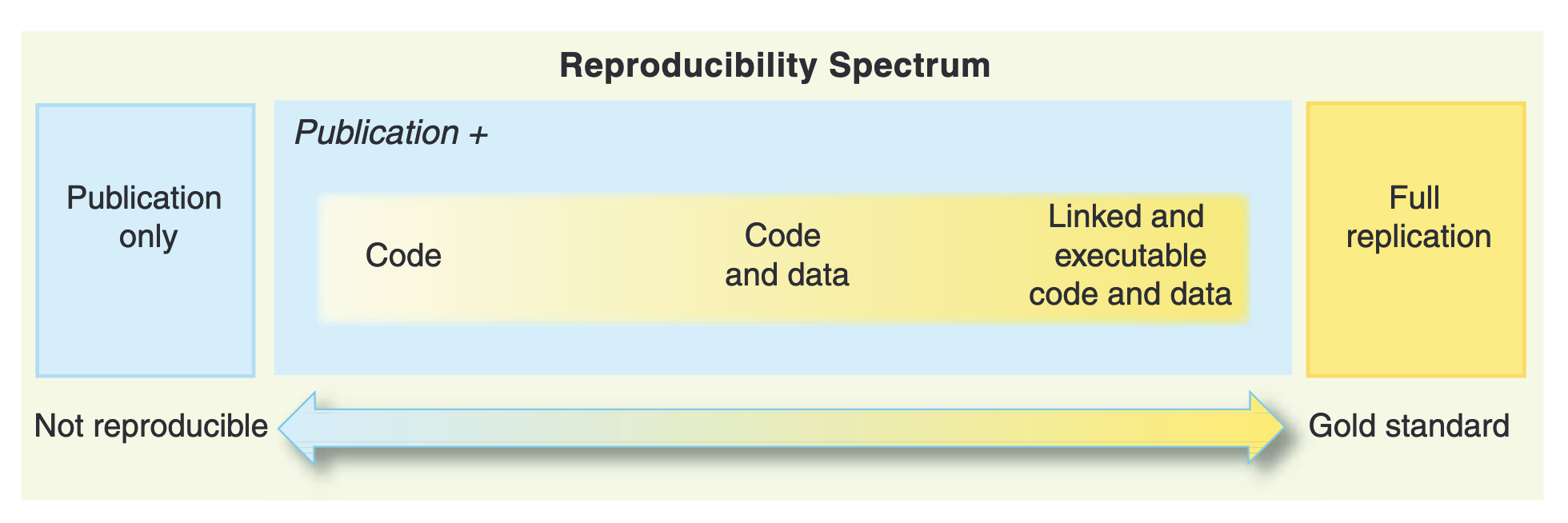
Une réflexion écosystémique de la reproductibilité
En lien avec les forges, les dépots de données, etc.
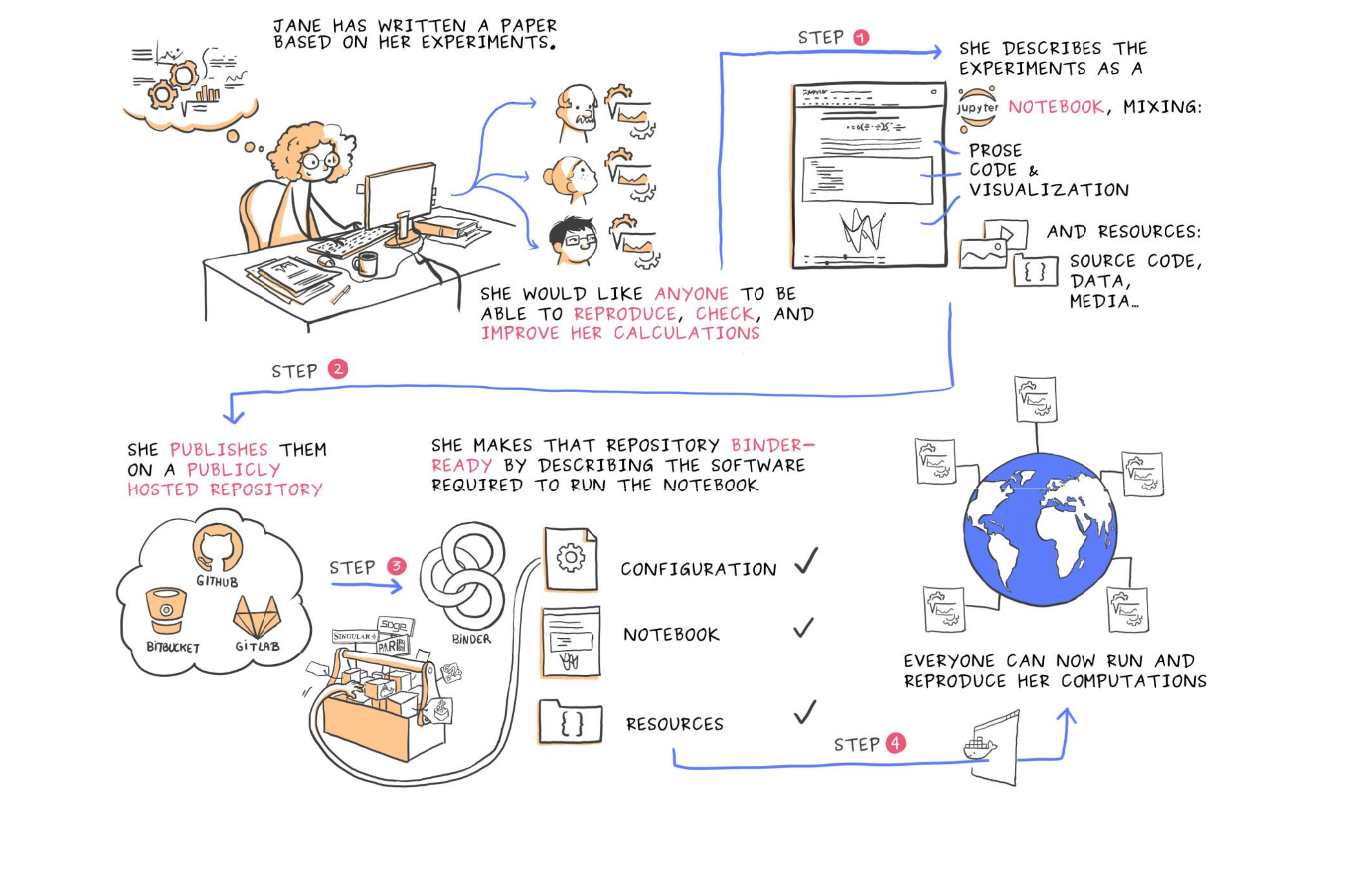
Juliette Taka and Nicolas M. Thiery. Publishing reproducible logbooks explainer comic strip. Zenodo. DOI: 10.5281/zenodo.4421040 (2018).
Le rôle d’interface des notebooks - le cas Google Colab
Accès à un écosystème + des ressources (dont GPU) depuis 2017 facilite les usages

Summarising 3 Years of Google Colab Usage — The Good, the Bad, and The Ugly
D’autres interfaces : HPC, etc. - le succès d’Onyxia
Utiliser des notebooks ? Un sujet polarisant
Notamment sur les aspects de reproductibilité
Tensions entre deux cultures : ingénierie logicielle et analyse de données

Une faible reproductibilité ?

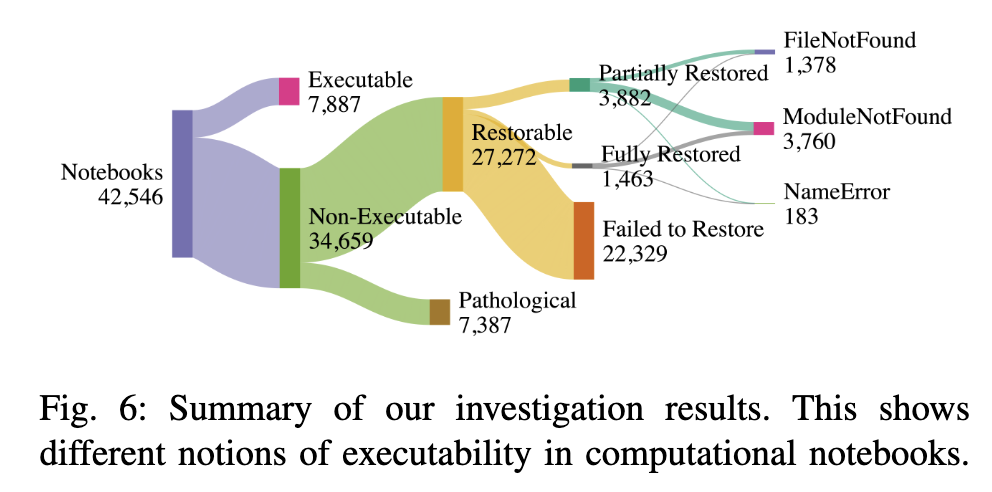
Des degrés de reproductibilité : paradigme spécifique aux notebooks interactifs qui n’est pas celui des logiciels (Nguyen et al. 2025).
Des pratiques bien installées là pour rester
Les notebooks computationnels sont intéressants pour l’exploration et l’explicitation des traitements
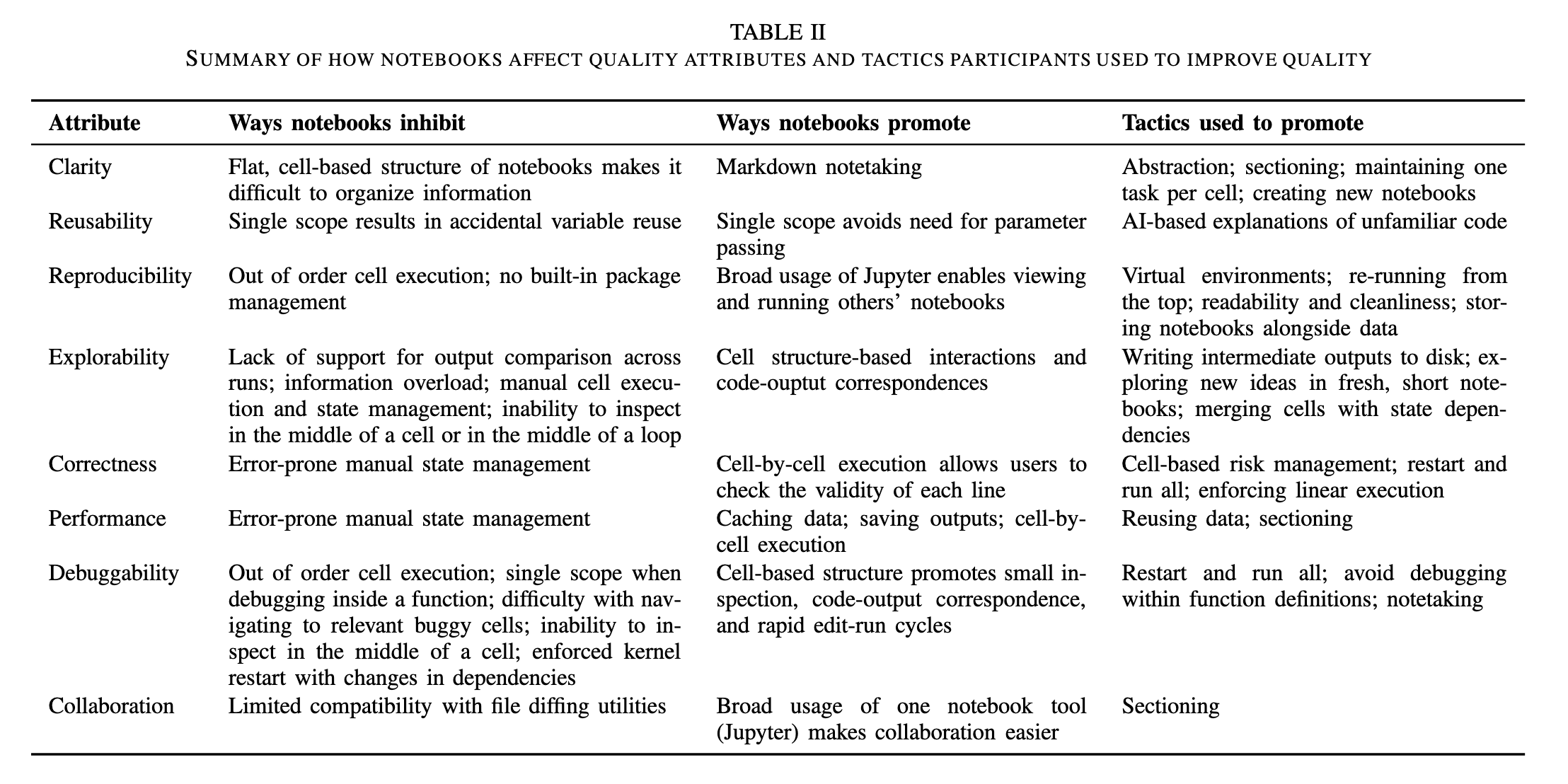
Huang, Ruanqianqian, Savitha Ravi, Michael He, Boyu Tian, Sorin Lerner, and Michael Coblenz. 2025. How Scientists Use Jupyter Notebooks: Goals, Quality Attributes, and Opportunities. arXiv:2503.12309. arXiv. https://doi.org/10.48550/arXiv.2503.12309. Huang et al. (2025)
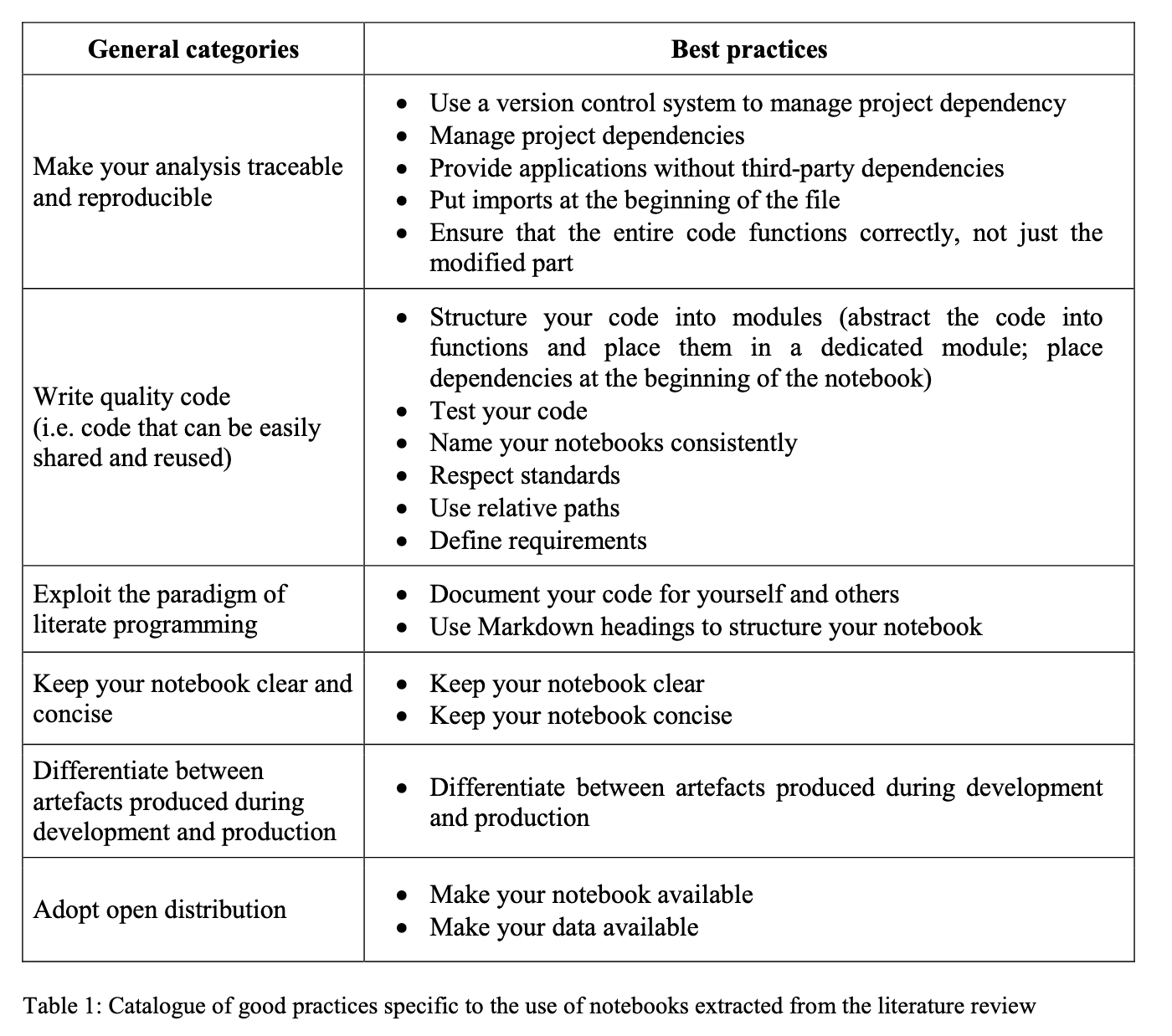
Des bonnes pratiques qui se stabilisent
Qui se rapprochent de pratiques générales de science ouverte
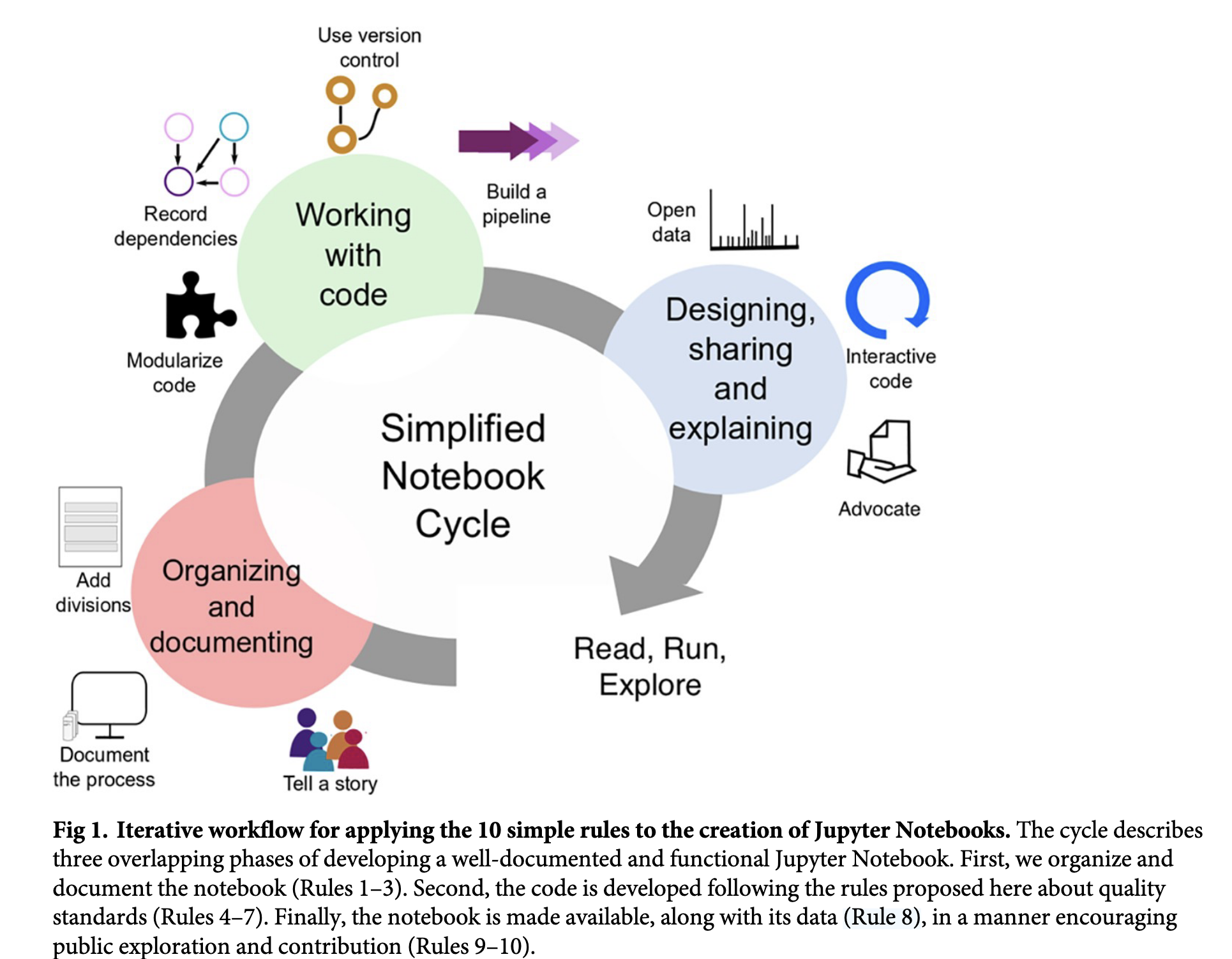
Ce qu’il manque actuellement
Beaucoup d’inconnues sur les pratiques (en général, et en particulier sur les notebooks)
- Les profils d’apprentissage de la programmation
- Quel effet de commencer par des notebooks ?
- Les conditions de bifurcation & de cohabitation
- Qu’est-ce qui déclenche le passage vers un autre format ? Comment les différents formats coexistent ?
- Les formes de réutilisation des notebooks
- Comment sont utilisés les notebooks publics existants ?
- Les usages avancés
- Comment se fait l’intégration dans d’autres outils : Quarto, Jupyter Book, etc. ?
L’IA dans les notebooks — trois mouvements à distinguer
- Copilotes intégrés : Cursor, Colab + Gemini, JupyterAI — suggestion de code dans l’éditeur
- Agents de notebook : nb-cli, génération et exécution autonome de cellules
- Le notebook comme contexte à prompt : le non-code (markdown, sorties précédentes) devient ressource pour le LLM

Opportunité : un notebook non reproductible reste réutilisable si le prompt et le contexte sont lisibles (Nguyen et al. 2025)
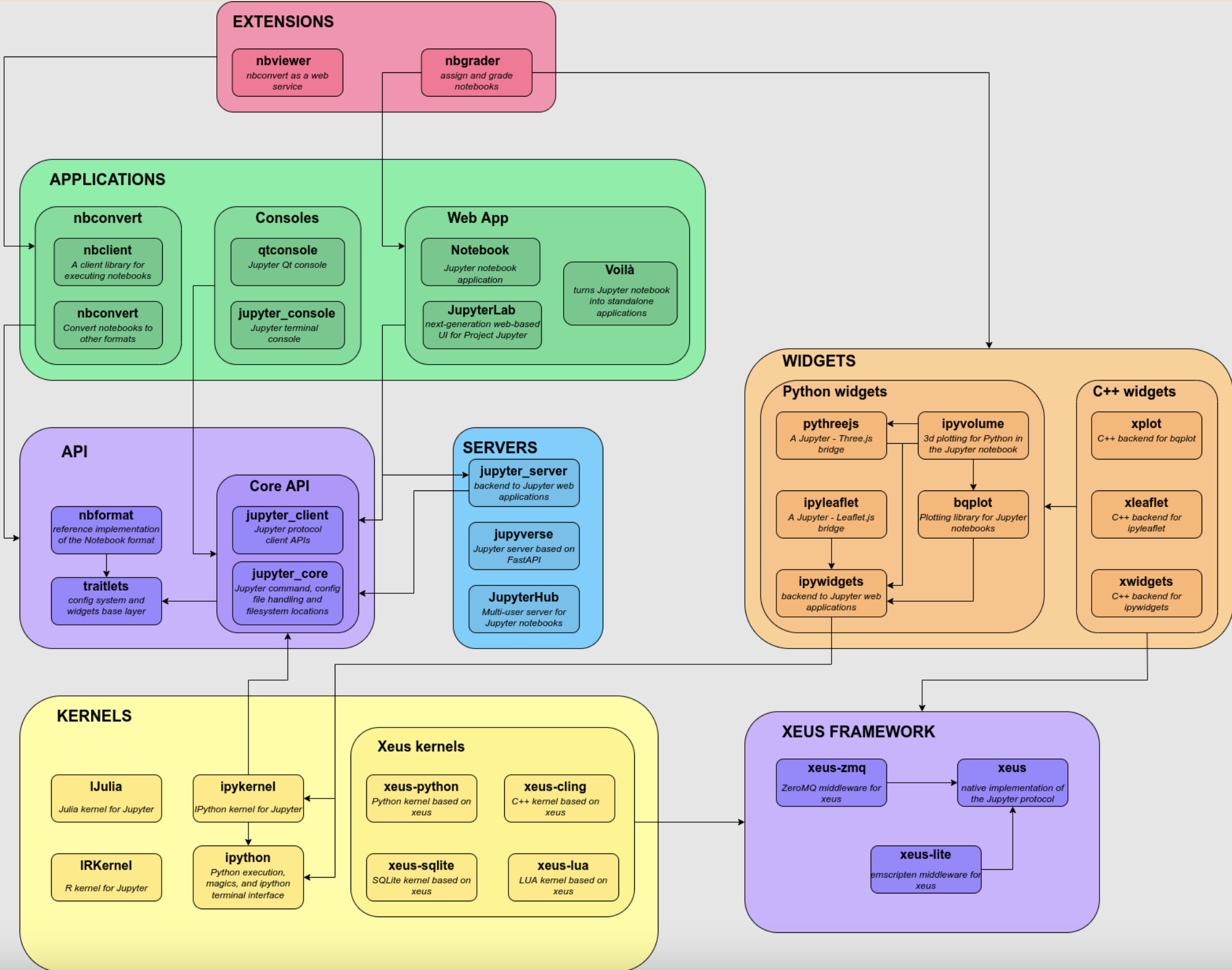
Annexe : L’écosystème Jupyter